[데이터 중심 애플리케이션 설계] 부하 대응 접근 방식
1) 부하 증가에 대한 대응
- 부하 매개변수가 어느 정도 증가하더라도 좋은 성능을 유지하려면 어떻게 해야 할까?
부하 수준 1단계에 적합한 아키텍처로는 10배의 부하를 대응할 수 없다.
급성장하는 서비스를 맡고 있다면 부하 규모의 자릿수가 바뀔 때마다
혹은 그보다 자주 아키텍처를 재검토해야 할지 모른다
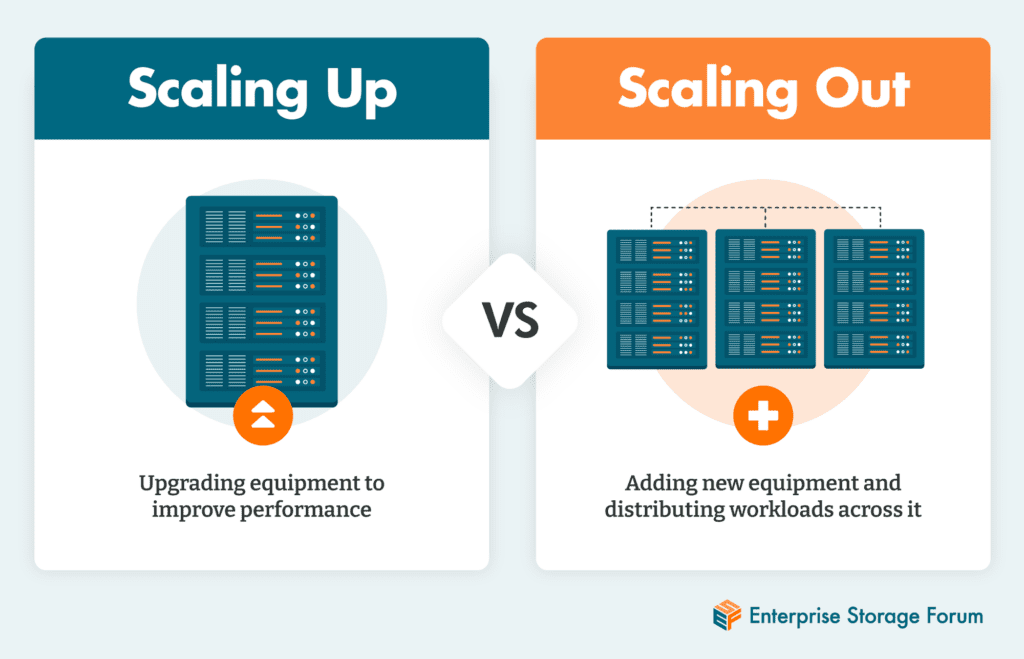
- 사람들은 확장성과 관련해 용량 확장(scale up), 규모확장(scaling out)으로 구분해서 말하곤 한다.
다수의 장비에 부하를 분산하는 아키텍처를 비공유 아키텍처라 부른다.
현실적으로 좋은 아키텍처는 실용적인 접근 방식의 조합이 필요하다.
예를 들어, 적절한 사양의 장비 몇 대가 다량의 낮은 사양 장비보다 여전히 훨씬 간단하고 저렴하다.
2) 탄력적 시스템 vs 비탄력적 시스템
- 일부 시스템은 탄력적(elastic)이다. 즉, 부하 증가를 감지하면 컴퓨팅 자원을 자동으로 추가할 수 있다.
반면 그렇지 않은 시스템은 수동으로 확장해야 한다.
탄력적인 시스템은 부하를 예측할 수 없을 만큼 높은 경우 유용하지만 수동으로 확장하는 시스템이 더 간단하고
운영상 예상치 못한 일이 더 적다.
- 다수의 장비에 상태 비저장(stateless) 서비스를 배포하는 일은 상당히 간단하다.
하지만 단일 노드에 상태 유지(stateful) 데이터 시스템을 분산 설치하는 일은 아주 많은 복잡도가 추가적으로 발생한다.
이런 이유로 확장 비용이나 데이터베이스를 분산으로 만들어야 하는 고가용성 요구가 있을 때까지
단일 노드에 데이터베이스를 유지하는 것(용량 확장)이 최근까지의 통념이다.
- 분산 시스템을 위한 도구와 추상화가 좋아지면서 이 통념이 적어도 일부 애플리케이션에서는 바뀌었다.
대용량 데이터와 트래픽을 다루지 않는 사용 사례에도 분산 데이터 시스템이 향후 기본 아키텍처로 자리 잡을
가능성이 있다.
3) 대규모 시스템 아키텍처의 특징

- 대개 대규모로 동작하는 시스템의 아키텍처는 해당 시스템을 사용하는 애플리케이션에 특화돼 있다.
범용적이고 모든 상황에 맞는 확장 아키텍처는 없다.
- 아키텍처를 결정하는 요소는 읽기의 양, 쓰기의 양, 저장할 데이터의 양, 데이터의 복잡도,
응답 시간 요구사항, 접근 패턴 등이 있다.
혹은 (대개) 이 요소 중 일부 조합에 더 많은 문제가 추가된 경우도 있다.
- 예를 들어, 각 크기가 1kb인 초당 100000건의 요청을 처리하도록 설계한 시스템과
각 크기가 2GB인 분당 3건의 요청을 처리하기 위해 설계한 시스템은
서로 같은 데이터 처리량이라 해도 매우 다르다.
- 특정 애플리케이션에 적합한 확장성을 갖춘 아키텍처는 주요 동작이 무엇이고
잘 하지 않는 동작이 무엇인지에 대한 가정을 바탕으로 구축한다.
이 가정은 곧 부하 매개변수가 된다.
- 이 가정이 잘못되면 확장에 대한 엔지니어링 노력은 헛수고가 되고 최악의 경우 역효과를 낳는다.
스타트업 초기 단계나 검증되지 않은 제품의 경우에
미래를 가정한 부하에 대비해 확장하기보다는
빠르게 반복해서 제품 기능을 개선하는 작업이 좀 더 중요하다.
-