아티클
Event Report list 장애 대응
깊게 생각하고 최선을 다하자
2024. 9. 14. 19:32

- 'Event Report list 장애 대응'을 STAR 프레임워크를 기반으로 진행해보았습니다.
- STAR 프레임워크는 특정 상황에서 목표를 달성하기 위한 전략적인 접근 방식으로,
주로 문제 해결 및 성과 평가 등에서 사용됩니다.
이 프레임워크는 상황(Situation), 작업(Task), 행동(Action), 결과(Result)의 네 가지 핵심 요소로 구성되어 있습니다.
1) 상황(Situation)
- QA 서버에서 프론트엔드 개발자가 Event Report List를 테스트중에
Pod Memory 및 JVM Heap 사용량이 급증하는 문제가 발생했습니다.
- 그리고 이 사실이 Grafana를 통해 모니터링되어 리포트되었습니다.


2) 작업(Task)
(1) 가설 수립
- 쿼리 문제: Service 클래스에서 반복문을 사용해 데이터를 추출하는 쿼리가 있었습니다.
- 이 쿼리는 O(N) 시간 복잡도로 동작합니다.
- API 요청이 급증하면 이 쿼리가 부하의 원인일 수 있다고 가설을 세우고, k6 테스트를 진행했습니다.
3) 행동(Action)
- DB 쿼리 리팩토링: 쿼리를 최적화하여 성능을 개선했습니다.
- QA 서버 배포 및 테스트: 기존 API와 리팩토링된 새 API를 모두 QA 서버에 배포하고,
각각에 대해 2차례 k6 테스트를 진행했습니다.
(1) 1차 k6 테스트
- 테스트 방법: 가상 사용자(VUser) 100명부터 시작하여, 100명씩 늘려가며 총 3차례 테스트를 진행했습니다.
(1-1) 1차 k6 테스트 결과
(1) API Latency 개선
- VUser 100명: http_req_duration 5.92s → 585.15ms (90% 개선)
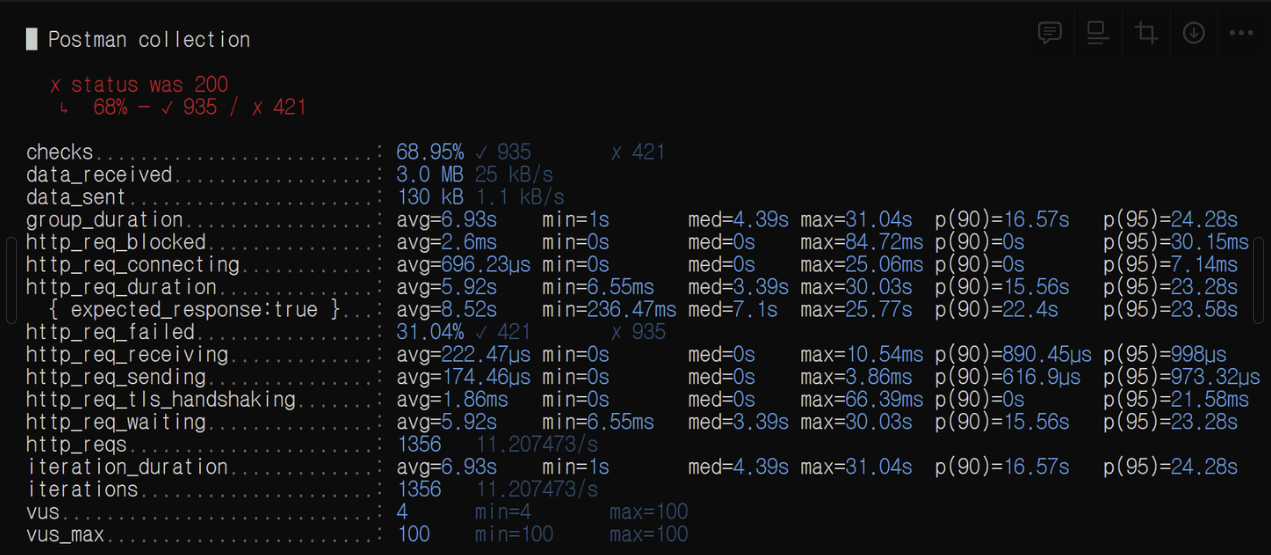

- VUser 200명: http_req_duration 4.7s → 1.57s (66.6% 개선)
- VUser 300명: http_req_duration 3.77s → 2.81s (25.47% 개선)
(2) Pod Memory 및 Heap Memory
- VUser 100명: 기존 API와 새 API 모두 동일한 수준
- VUser 200명: 기존 API와 새 API 모두 동일한 수준
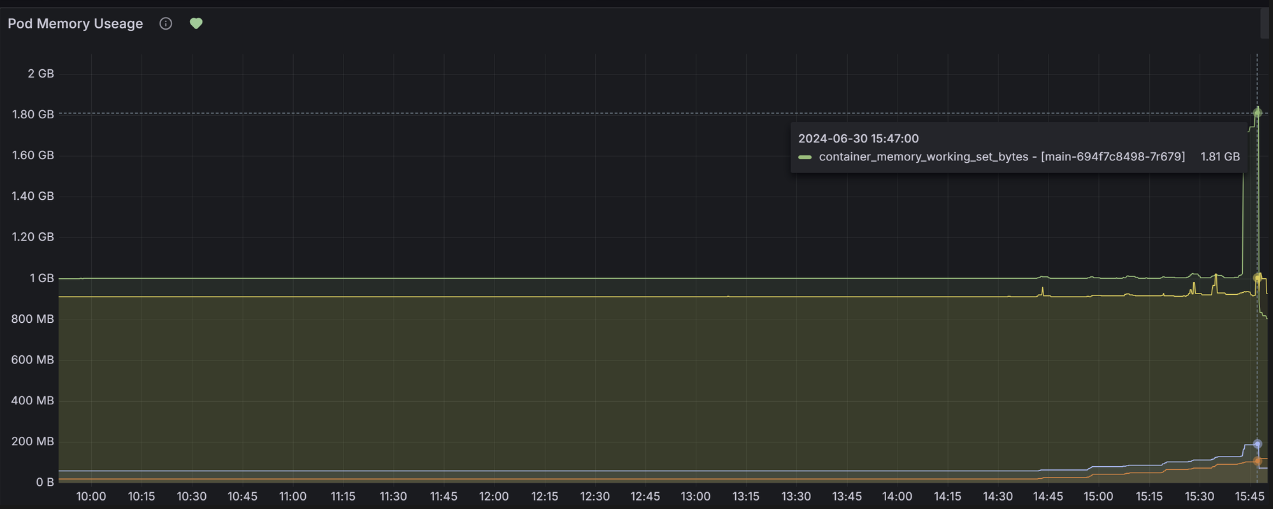
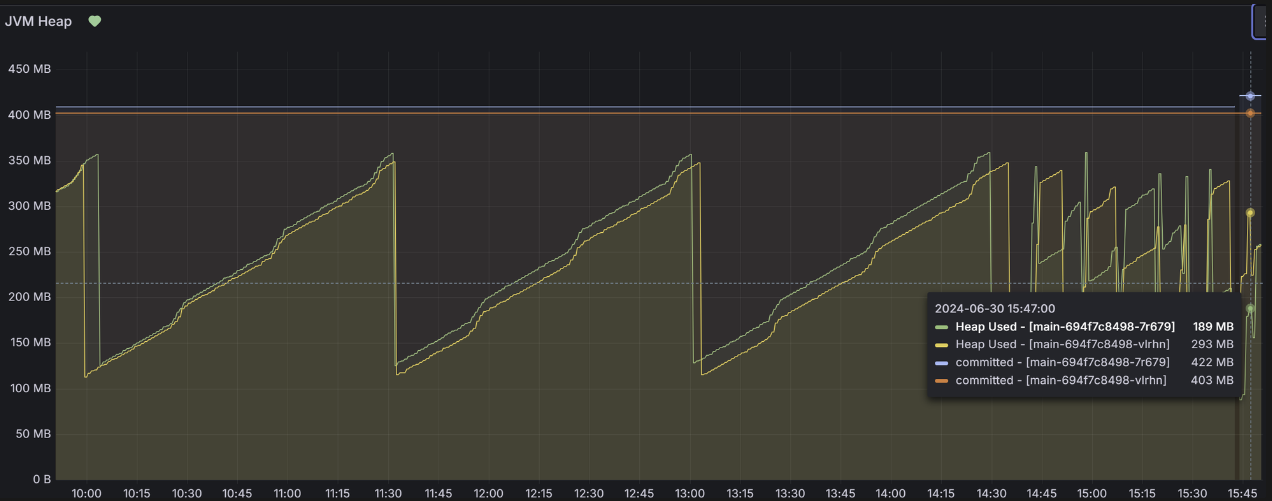
- VUser 300명: 기존 API와 새 API 모두 Pod Memory, Heap Memory 급증 현상 (900MB → 1.8~1.9GB)
[Pod Memory]
[Heap Memory]
(1-2) 1차 테스트 결과 해석
- API Latency: 새 API가 기존 API에 비해 평균 60.69% 성능이 향상되었습니다.
- Pod Memory: 기존 API와 새 API 둘 다 VUser 300명 요청부터 급증하는 현상이 나타났습니다.
- Heap Memory: 기존 API와 새 API 둘 다 VUser 300명 요청부터 급증하는 현상을 보였습니다.
(1-3) 1차 테스트 결론
- 쿼리 튜닝만으로는 문제 상황에 대한 적절한 대응책이 아니었습니다.
- 특히 VUser 300명일 때, Pod Memory, Heap Memory 사용량이 급증하여 문제가 발생했습니다.
- 따라서, API 요청의 임계점을 잘 파악해야합니다.
- 그에 맞추어 Pod 다중화 또는 Pod Memory Spec-up을 고려해야합니다.
(2) 2차 k6 테스트
- 1차 테스트의 문제점:
- 실제 페이지에서는 단일 API 호출이 아니라 여러 API 호출이 동시에 발생합니다.
- 1차 테스트는 실제 Prod 환경과 다르다는 문제가 있었습니다.
- 2차 테스트 목표:
- 실제 API 호출 패턴을 반영하여, Pod Memory 및 Heap Memory의 변화를 측정합니다.
- 테스트는 VUser 20명으로 설정하고, API 호출 간격을 1초로 설정했습니다.
(2-1) 2차 k6 테스트 수행
- 테스트 설정:
- VUser 20명, Duration 2분, 사용자 API 호출 간격 1초로 테스트 진행.
- 테스트 결과:
- 기존 API와 새 API 모두 Pod Memory 및 Heap Memory에서 큰 변화가 없었습니다.
(2-2) 2차 k6 테스트 결론
- 기존 장애 상황과 최대한 유사하게 문제를 재현하였으나,
Pod Memory 및 Heap Memory 사용량이 급증하는 문제를 재현할 수 없었습니다.
4) 결과(Result)
- k6 테스트로 기존 장애 상황이 완전히 재현되지 않아서, 명확하게 문제를 정의해내기 어려웠습니다
-> 인프라 팀 담당자와 회의 결과, 순간적으로 다량의 API 요청을 보내서 발생했을 가능성이 가장 높다고 결론내렸습니다.
-> 다만, 그러한 API 요청이 실제 Prod 환경에서 고객에 의해 재현될 가능성은 낮기 때문에,
우선적으로 지속적으로 모니터링하면서 대응하는 것으로 합의하였습니다.
-하지만, 해당 문제 정의 및 해결 과정에서
기존 API에 대한 쿼리 튜닝을 통해서 API 성능을 개선하는 성과를 얻을 수 있었습니다.